I was chatting to some makers over at make.offerzen.com about some of the more fun projects I’ve gotten myself into the past year and it occurred to me that I’ve been leaning on ElasticSearch quite a bit without really noticing it. I guess that’s the way things go when an implementation works so well after a while, you don’t even have to think about potential alternatives.
It all started, as most of my adventures do, with me trying to get better at something that I have absolutely no clue about. I was first introduced to the concept of ES by a project at work where the client decided to use Vulcan for their search needs. It worked pretty great and soon I was building cool asset libraries with event listeners doing all kinds of nifty things plugging into ES. I really would have preferred to built it out with Episerver Find instead which can do amazing personalization on top of all that, but regardless both of these make use of ES behind the scenes.
Me being me I promptly decided I wanted to do something with plain ES, I’ve always found that to be the best way to figure out which nifty features come from ES and which of them come from Find or Vulcan (for example). But what the heck should I do with ElasticSearch?
First I decided a forum I regular really needed a bot which could react to remindme commands, mainly so that it could tell me to look at cool stuff after I get home from work. Fortunately, the forum runs on Discourse which has a well documented and somewhat oversharing API. I spun up NEST and got to work.


While building it out I also realised that it would be a great resource for some data visualization fun with Kibana which got me more exited. That part of the bot is still my favourite, I’ve got a quarterly “analysis” post where I compare things like forum average daily engagement, sentiment, and most active posters to the last quarter. Great fun.
I called the ES powered bot Tyrell (because Blade Runner) and released it as my first big open source release on github.
I found it super easy to work with NEST and ES, so easy in fact that I soon built an Instagram scraper which gets email accounts from users that have it in their bio or contact details (for science) and also released that on github. After that, I’ve built out a few more things that rely on ES, which I haven’t released yet ;).
This was all fair and well, indexing a few thousand forum posts a month and some emails now and again. Still pretty tame for what ES could apparently really handle.
Some backstory is needed here, a couple of months before all of this I launched probably the biggest solo project I’ve ever undertaken. In about 3 months of after-hours dev time I’d built a fully cloud-based multi-tenant customizable social media management platform, fancy way of saying it’s a stripped down CMS that each user can customize however they see fit (within a given structural framework) to receive and manage images that they want to share on their social media. My “startup” was picked up by Google and they gave me a bunch of Google Cloud Platform credits to host it (and anything else I could imagine) on their clouds, thanks again Google.
I thought to myself wait a minute, I’ve potentially got all these Google Cloud servers, what If I take the Instagram scraper code and turn it onto something that scrapes hashtags instead.
A couple of days later I had built some form of an AI/ML scraper that would load up Instagram hashtags based on it’s own “exploration” of the site, analyse how popular the hashtag and recent media related to that hashtag are (and how well they were doing relative to other recent hashtags) and then store all of that data in ES. I could then create a simple tool that queried ES to find the best related hashtags based on a given request. Money.
I built the tool and plugged it into the aforementioned big-ass-project, which may or may not still be available for you to play with over at https://socialshard.com/tools/hashtag-explorer. *Disclaimer *I don’t focus on the project at all anymore, and the crawlers are all dead so the data may be dated; I may edit this post later once the site is down with just that query page as I like having that data in ES regardless.*
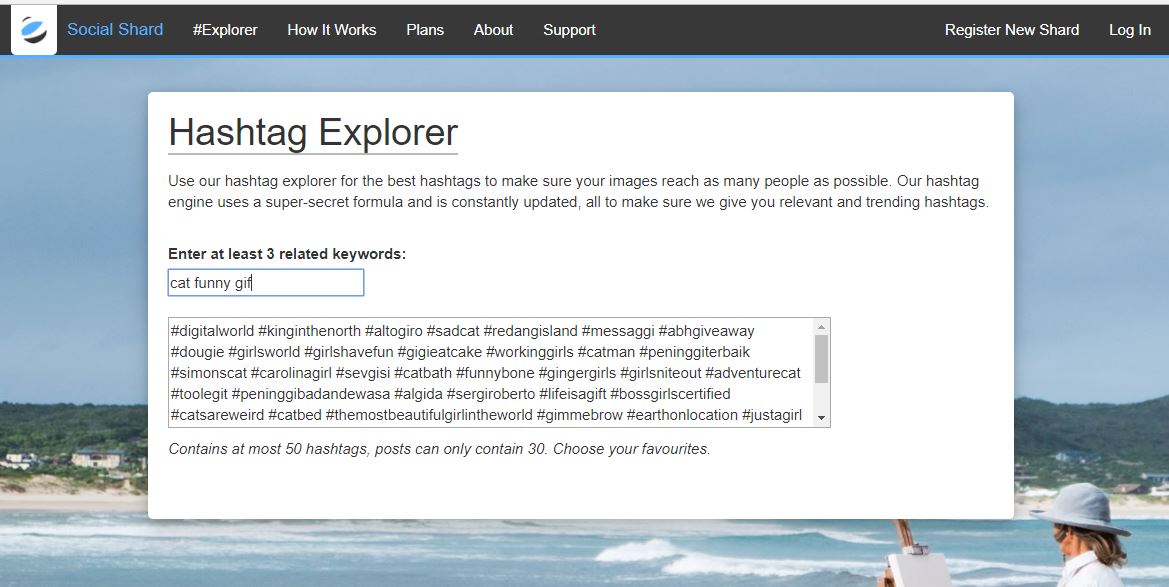
That’s the long boring backstory part done, the more interesting part (to me) was getting all that hashtag analytic data into ES. How much data? well, quite a bit.

At peak I was running 8 crawler nodes 24/7, each doing about 1 hashtag “overview” page load every 1.4 seconds (to beat the rate limiting). An example of the page load looked like this: https://www.instagram.com/explore/tags/cat/, it should also be noted that all this info is available publicly so none of the crawler nodes need Instagram API keys or even user accounts.
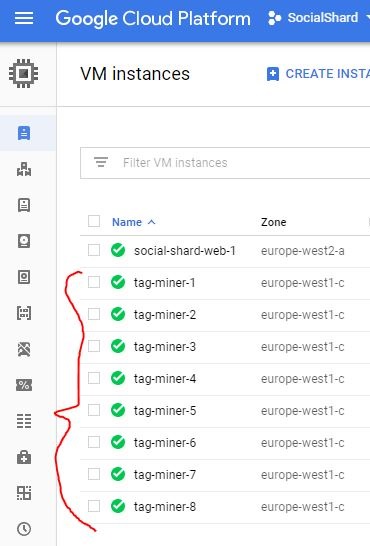
These low spec Debian nodes only needed to do one thing. Run the dotnet core crawler program and report all the data to one ES master node, at a pretty alarming rate it turns out.
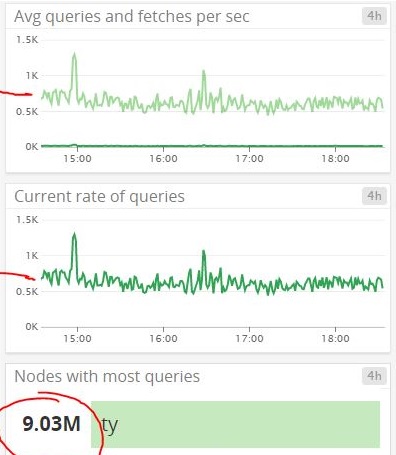
Turns out we would be averaging somewhere between 500-700 ElasticSearch queries per second. (You might be wondering how 8 nodes at 1 page every 1.4 seconds translates to that many queries; nerd. Simple answer is I built it to only check a hashtag once every 24 hours, so most of the traffic is “Hey can I scan this again?” filtering type requests).
The interesting part is that I’ve got a few other services that run off that same ES master node (such as Tyrell) and they all seemed to be performing as fast as they always have. It seems to be taking a hammering in its stride.
Ready for the kicker?
The ES master node runs on a seriously tiny SSD VPS with a single 2.4ghz vCore and 4GB RAM. That may be the only thing it runs, but I still can’t believe that it didn’t just fall over every 17 minutes. (Now before some other ES nerds come here and spoil the fun saying other nodes can process queries as well, just note I don’t have any other permanently connected nodes. I manually connect them up now and again to serve as a backup of the ES indexes).
Elasticsearch Is Fast. Really, Really Fast.
Well, they didn’t lie.
Thanks for stopping by.